Intro
Solstory consists of three components: A Solana Program sitting on chain, a JS api to interact with it, and an off-chain component managed by a common data standard to make it compatible with api clients and display programs. A fourth component, a CDN layer, sits on top for performance.
The solana program manages what is effectively a horizontally scalable set of sidechains, one per writer-nft combo. The JS API simplifies working with this program and impements the data standard. The data standard ensures that off chain data stored as part of solstory remains cross compatible with all the different viewers who might want to look at it.
You're free to (and encouraged to, please opensource!) reimplement the JS api–
the solana program will enforce verification constraints. You're also free
to ignore the data standard, except then no one will be able to display your
data and if you break it enough no one will be able to read your writer's
sidechains at all, which sort of defeats the purpose (if you're using
solstory as a cheap and simple way of attaching offchain data to NFTs for your
own internal use, this might make sense, and in fact we provide compatibility
for this with the visible flag, see permissioning.
Capabilities
While metadata is mutable, Solstory stories/chains themselves only supports two capabilities: read, and append. This is so that an attached story can be a provable record of value for an NFT.
Overall Architecture
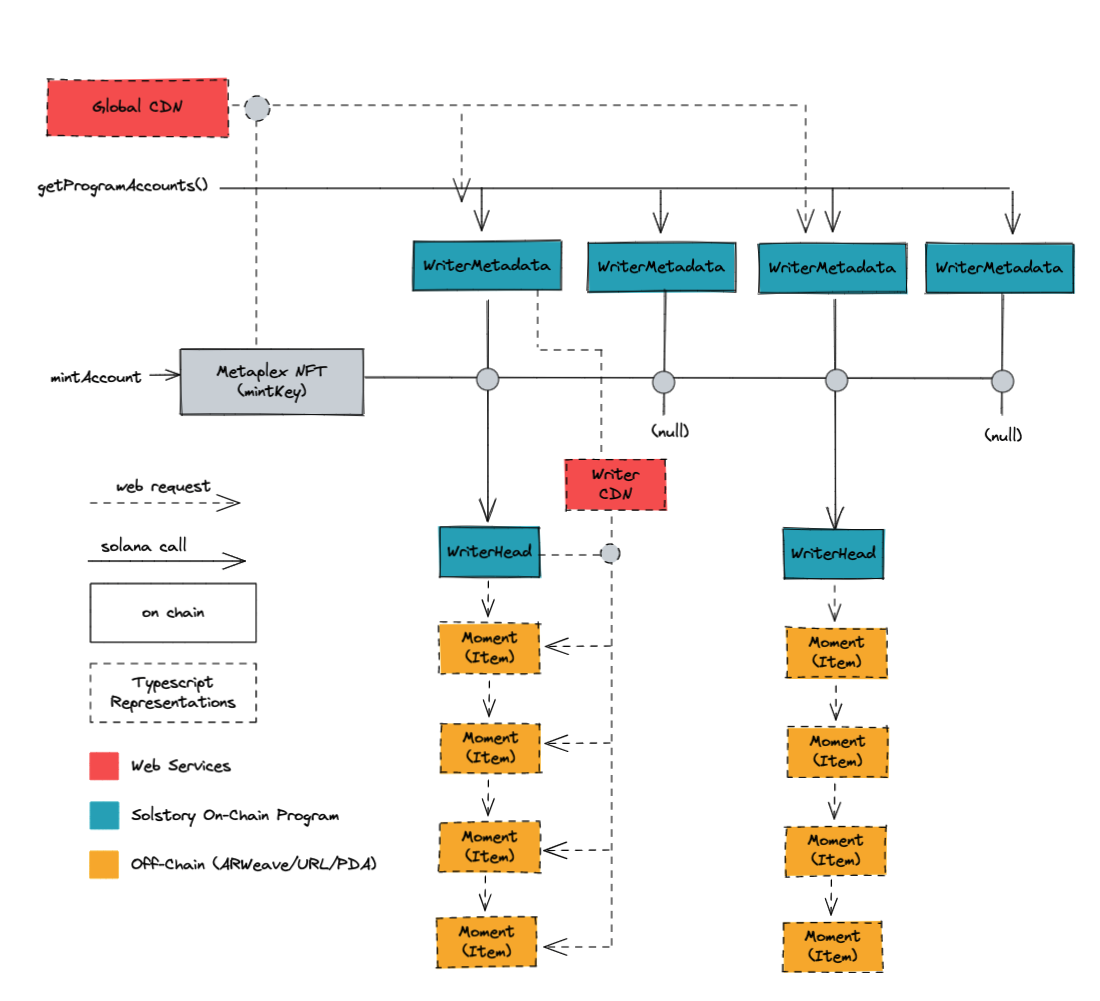
Here's an overview of the entire architecture, from the perspective of a client who's trying to get all the stories associated with an NFT. We'll explain the details of this in the architecture section. With individual images of this overview. (Coming soon)
In this picture, the Solana program's PDAs are in blue, the off-chain data is in yellow, and the api client operates the lines (both solid and dashed) in between. The fourth layer, the optional CDNs, are in red.